関数型プログラミングでは、メモリ効率の高いコレクションの非破壊操作をどのように実現するのでしょうか?
 https://stackoverflow.com/questions/1993760
https://stackoverflow.com/questions/1993760
-
22-09-2019 - |
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
Russian質問
私は、大規模なコレクションの非破壊操作が関数型プログラミングでどのように実装されるかを理解しようとしています。完全に新しいコレクションを作成せずに、単一の要素を変更または削除できる方法。変更されていない要素も含めてすべての要素がメモリ内に複製されます。(元のコレクションがガベージ コレクションされたとしても、そのようなコレクションのメモリ フットプリントと全体的なパフォーマンスはひどいものになると予想されます。)
これが私が今までに到達した距離です:
F#を使って関数を思いつきました insert これは、リストを 2 つの部分に分割し、その間に新しい要素を導入しますが、変更されていない要素をすべて複製することはないようです。
// return a list without its first n elements:
// (helper function)
let rec skip list n =
if n = 0 then
list
else
match list with
| [] -> []
| x::xs -> skip xs (n-1)
// return only the first n elements of a list:
// (helper function)
let rec take list n =
if n = 0 then
[]
else
match list with
| [] -> []
| x::xs -> x::(take xs (n-1))
// insert a value into a list at the specified zero-based position:
let insert list position value =
(take list position) @ [value] @ (skip list position)
次に、.NET を使用して、元のリストのオブジェクトが新しいリストで「リサイクル」されているかどうかを確認しました。 Object.ReferenceEquals:
open System
let (===) x y =
Object.ReferenceEquals(x, y)
let x = Some(42)
let L = [Some(0); x; Some(43)]
let M = Some(1) |> insert L 1
次の 3 つの式はすべて次のように評価されます。 true, によって参照される値であることを示します。 x リストの両方で再利用されます L そして M, 、つまり。この値のコピーがメモリ内に 1 つだけ存在することを確認します。
L.[1] === x
M.[2] === x
L.[1] === M.[2]
私の質問:
関数型プログラミング言語は通常、新しいメモリ位置に値を複製するのではなく、値を再利用するのでしょうか、それとも F# の動作が単に幸運だったのでしょうか?前者を仮定すると、メモリ効率の高いコレクションの編集を関数型プログラミングでどの程度合理的に実装できるでしょうか?
(ちなみに:については知っています クリス・オカサキさんの本 純粋に機能的なデータ構造, 、しかしまだじっくり読む時間がありません。)
解決
私はどのように把握しようとしています 大型の非破壊操作 コレクションはで実装されています 関数型プログラミング、すなわち。どうですか? 単一の変更または除去することができます Aを生成することなく要素 すべて完全に新しいコレクション 要素も変更されていないもの、 メモリに複製されます。
F#でいくつかの説明とデータ構造の実装を持っているのこのページ。それは本の中で存在していなかったので、AVL木は私自身の実装であるが、それらのほとんどは、のOkasakiのの純粋に機能的なデータ構造から来ています。
type 'a tree =
| Node of 'a tree * 'a * 'a tree
| Nil
let rec insert v = function
| Node(l, x, r) as node ->
if v < x then Node(insert v l, x, r) // reuses x and r
elif v > x then Node(l, x, insert v r) // reuses x and l
else node
| Nil -> Node(Nil, v, Nil)
注は、私たちがいることを私たちのノードの一部を再利用します。我々はこの木で始めましょう。
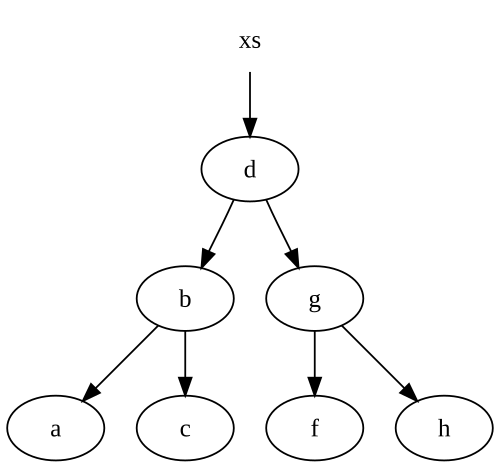
私たちはツリーにe挿入し、我々は、元の木に背中を向けたノードの一部とブランドの新しいツリーを取得する場合:

私たちは、上記xsツリーへの参照を持っていない場合は、.NET意志ごみ収集ライブ言及せずに任意のノード、特にthed、gとfノードます。
私たちは私たちの唯一の挿入されたノードの経路に沿ってノードを変更したことに注意してください。これは、リストを含むほとんどの不変のデータ構造、ではかなり一般的です。だから、私たちが作成したノードの数は正確に我々はデータ構造に挿入するために横断する必要があるノードの数と同じです。
関数型プログラミング言語を実行します。 一般的に再利用値の代わりに、 新しいメモリ位置にそれらをクローニングし、 または私はF# 'sのちょうどラッキーでした 動作?元と仮定すると、あります この方法を合理的にメモリ効率 コレクションの編集が可能 関数型プログラミングで実装?
はいます。
それらのほとんどの非自明な操作はO(N)時間を必要とするので、リストは、しかしながら、非常に良好なデータ構造ではない。
平衡二分木は、我々はすべての挿入時にO(ログn)のコピーを作成する意味、O(ログn)の挿入をサポートしています。ログ 2 (10 ^ 15)〜= 50であるので、オーバーヘッドは、これらの特定のデータ構造のために非常に非常に小型です。あなたが挿入/削除した後、すべてのオブジェクトのすべてのコピーを周りに保つ場合でも、あなたのメモリ使用量は、Oの割合で増加(N Nログ)します - 非常に合理的な、私の意見では、
。他のヒント
すべての要素 (未変更のものを含む) がメモリ内に複製される、完全に新しいコレクションを作成せずに、単一の要素を変更または削除できる方法。
これは、コレクションの種類に関係なく、 ポインタ 要素へのデータは、要素自体とは別に保存されます。(例外:一部のコンパイラは最適化を行う場合もありますが、コンパイラは自分が何をしているのかを知っています。) したがって、たとえば、最初の要素のみが異なり、末尾を共有する 2 つのリストを持つことができます。
let shared = ["two", "three", "four"]
let l = "one" :: shared
let l' = "1a" :: shared
これら 2 つのリストには、 shared 部分的には共通ですが、最初の要素は異なります。あまり明らかではありませんが、各リストは、多くの場合「コンス セル」と呼ばれる一意のペアでも始まることです。
リスト
lへのポインタを含むペアで始まります"one"そして共有テールへのポインタ。リスト
l'へのポインタを含むペアで始まります"1a"そして共有テールへのポインタ。
宣言さえしていたら l そしてしたかった 最初の要素を変更または削除する 取得するため l', 、次のようにします。
let l' = match l with
| _ :: rest -> "1a" :: rest
| [] -> raise (Failure "cannot alter 1st elem of empty list")
一定のコストがかかります。
スプリット
lコンスセルを調べて、その頭と尾を調べます。を指す新しいコンス セルを割り当てます。
"1a"そして尻尾。
新しいコンスセルはリストの値になります l'.
大きなコレクションの途中で点のような変更を行う場合は、通常、対数の時間と空間を使用するある種のバランスの取れたツリーを使用することになります。頻度は低いですが、より洗練されたデータ構造を使用することもあります。
ジェラール・ユエの ジッパー は、ほぼすべてのツリー状のデータ構造に対して定義でき、一定のコストでトラバースして点状の変更を行うために使用できます。ジッパーがわかりやすいですね。
パターソンとヒンゼの フィンガーツリー はシーケンスの非常に洗練された表現を提供しており、これにより途中の要素を効率的に変更できるようになりますが、理解するのは困難です。
参照しているオブジェクトは、あなたのコード内で同じですが、
私は自分自身のための参照の収納スペースを信じ
そして、リストの構造
takeによって複製されます。
結果として、参照されるオブジェクトは同じであるが、
そして、尾は二つのリストの間で共有されています、
最初の部分のための「セル」は複製されます。
私は関数型プログラミングの専門家ではありませんよ、 多分あなたが達成できた木のいくつかの種類と のみログ(n)の要素の複製、 あなたは、ルートからのパスのみを再作成しなければならないとして、 挿入要素に
それは私に聞こえます。データが実際に純粋に機能的なコードで必ずしも不変である(参照参照透明に)、しかし私は(Haskellはあなたの場合はそういったことのように、最も近いが)どこでも絶対的な純度を強制する任意の非おもちゃの言語を認識していないよ。
大まかに言えば、参照透明性手段は実用的な違いは、変数/発現およびそれが/評価さを保持している値との間での存在しないこと。ます(定義)不変データの一部を変更することはありませんので、それは自明その値で識別することができ、同じ値を持つ他のデータから何時の間にか振る舞うべき。
同様に、不変ののデータ構造のその構造(ではないが、その内容)の固有参照透明性を有しています。構造の部分が安全だけでなく、新たな構造で再利用することができ、この手段は、すべて含まれている値も不変であると仮定します。例えば、短所リストの末尾には、多くの場合、再利用することができます。あなたのコードでは、私はそれを期待します:
(skip 1 L) === (skip 2 M)
再利用かかわらず、常に可能なわけではありません。あなたのskip機能によって除去リストの最初の部分は、本当に例えば、再利用することはできません。それがnullで終わる文字列を連結すると問題に似て全く新しいリストを再構築しなければならないのと同じ理由で、短所リストの最後に何かを追加すると、高価な操作です。
私はあなたがC#と少なくとも多少慣れていると仮定するつもりです。計り知れないほどのエリックリペットはhref="http://blogs.msdn.com/ericlippert/archive/tags/Immutability/default.aspx" rel="nofollow noreferrer">スルーポストのは不変データにを
関数型プログラミング言語の式の削減戦略に興味があるかもしれません。このテーマに関する良い本は、 関数型プログラミング言語の実装, 、Haskell の作成者の 1 人である Simon Peyton Jones による。特に次の章をご覧ください ラムダ式のグラフ削減 これは、共通の部分式の共有について説明しているためです。お役に立てば幸いですが、残念ながらこれは遅延言語にのみ適用されます。
