Как достигается эффективное с точки зрения памяти неразрушающее манипулирование коллекциями в функциональном программировании?
 https://stackoverflow.com/questions/1993760
https://stackoverflow.com/questions/1993760
-
22-09-2019 - |
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
RussianВопрос
Я пытаюсь понять, как неразрушающее манипулирование большими коллекциями реализовано в функциональном программировании, т.е.как можно изменять или удалять отдельные элементы без необходимости создания совершенно новой коллекции, где все элементы, даже неизмененные, будут дублироваться в памяти.(Даже если исходная коллекция будет собрана из мусора, я бы ожидал, что объем памяти и общая производительность такой коллекции будут ужасными.)
Вот как далеко я продвинулся до сих пор:
Используя F #, я придумал функцию insert это разбивает список на две части и вводит новый промежуточный элемент, по-видимому, без клонирования всех неизмененных элементов:
// return a list without its first n elements:
// (helper function)
let rec skip list n =
if n = 0 then
list
else
match list with
| [] -> []
| x::xs -> skip xs (n-1)
// return only the first n elements of a list:
// (helper function)
let rec take list n =
if n = 0 then
[]
else
match list with
| [] -> []
| x::xs -> x::(take xs (n-1))
// insert a value into a list at the specified zero-based position:
let insert list position value =
(take list position) @ [value] @ (skip list position)
Затем я проверил, "перерабатываются" ли объекты из исходного списка в новые списки, используя .net's Object.ReferenceEquals:
open System
let (===) x y =
Object.ReferenceEquals(x, y)
let x = Some(42)
let L = [Some(0); x; Some(43)]
let M = Some(1) |> insert L 1
Все следующие три выражения вычисляются как true, указывающий на то , что значение , на которое ссылается x повторно используется как в списках, так и в L и M, т.е.что в памяти есть только 1 копия этого значения:
L.[1] === x
M.[2] === x
L.[1] === M.[2]
Мой вопрос:
Обычно ли языки функционального программирования повторно используют значения вместо того, чтобы клонировать их в новую ячейку памяти, или мне просто повезло с поведением F #?Предполагая первое, является ли это тем, насколько разумно эффективное с точки зрения памяти редактирование коллекций может быть реализовано в функциональном программировании?
(Кстати.:Я знаю о Книга Криса Окасаки Чисто функциональные структуры данных, но у меня еще не было времени внимательно прочитать его.)
Решение
Я пытаюсь выяснить, как неразрушающее манипулирование большими коллекциями реализовано в функциональном программировании, т.е.как можно изменять или удалять отдельные элементы без необходимости создавать совершенно новую коллекцию, в которой все элементы, даже неизмененные , будут дублироваться в памяти.
Эта страница содержит несколько описаний и реализаций структур данных в F #.Большинство из них родом из Окасаки. Чисто Функциональные структуры данных, хотя дерево AVL является моей собственной реализацией, поскольку оно не присутствовало в книге.
Теперь, поскольку вы спросили о повторном использовании неизмененных узлов, давайте возьмем простое двоичное дерево:
type 'a tree =
| Node of 'a tree * 'a * 'a tree
| Nil
let rec insert v = function
| Node(l, x, r) as node ->
if v < x then Node(insert v l, x, r) // reuses x and r
elif v > x then Node(l, x, insert v r) // reuses x and l
else node
| Nil -> Node(Nil, v, Nil)
Обратите внимание, что мы повторно используем некоторые из наших узлов.Допустим, мы начнем с этого дерева:
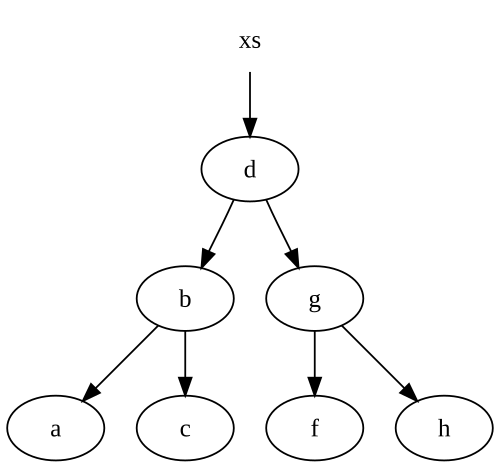
Когда мы вставляем e в дереве мы получаем совершенно новое дерево, с некоторыми узлами, указывающими назад на наше исходное дерево:

Если у нас нет ссылки на xs дерево выше, затем .NET будет собирать мусор для любых узлов без живых ссылок, в частности дляd, g и f узлы.
Обратите внимание, что мы изменили только узлы вдоль пути нашего вставленного узла.Это довольно типично для большинства неизменяемых структур данных, включая списки.Таким образом, количество создаваемых нами узлов в точности равно количеству узлов, которые нам нужно пройти, чтобы вставить в нашу структуру данных.
Используют ли функциональные языки программирования обычно повторно значения вместо клонирования их в новую ячейку памяти, или мне просто повезло с поведением F # ?Предполагая первое, является ли это разумной экономией памяти редактирование коллекций может быть реализовано в функциональном программировании?
ДА.
Списки, однако, не очень хорошая структура данных, поскольку большинство нетривиальных операций над ними требуют O (n) времени.
Сбалансированные бинарные деревья поддерживают O (log n) вставок, что означает, что мы создаем O (log n) копий при каждой вставке.Начиная с журнала2(10 ^ 15) равно ~ = 50, накладные расходы очень, очень малы для этих конкретных структур данных.Даже если вы сохраните все копии каждого объекта после вставки / удаления, использование вашей памяти будет увеличиваться со скоростью O (n log n) - на мой взгляд, очень разумно.
Другие советы
Как можно изменить или удалить отдельные элементы без необходимости создания совершенно новой коллекции, в которой все элементы, даже немодифицированные, будут дублироваться в памяти.
Это работает, потому что независимо от типа коллекции указатели элементы хранятся отдельно от самих элементов.(Исключение:некоторые компиляторы время от времени оптимизируют, но они знают, что делают.) Так, например, вы можете иметь два списка, которые отличаются только первым элементом и имеют общие хвосты:
let shared = ["two", "three", "four"]
let l = "one" :: shared
let l' = "1a" :: shared
Эти два списка имеют shared части общие, а их первые элементы различны.Менее очевидно то, что каждый список также начинается с уникальной пары, часто называемой «минус-ячейкой»:
Список
lначинается с пары, содержащей указатель на"one"и указатель на общий хвост.Список
l'начинается с пары, содержащей указатель на"1a"и указатель на общий хвост.
Если бы мы только заявили l и хотел изменить или удалить первый элемент получить l', мы бы сделали это:
let l' = match l with
| _ :: rest -> "1a" :: rest
| [] -> raise (Failure "cannot alter 1st elem of empty list")
Существуют постоянные затраты:
Расколоть
lв его голову и хвост, исследуя минусовую ячейку.Выделите новую ячейку минусов, указывающую на
"1a"и хвост.
Новая ячейка cons становится значением списка l'.
Если вы вносите точечные изменения в середине большой коллекции, обычно вы будете использовать своего рода сбалансированное дерево, использующее логарифмические время и пространство.Реже вы можете использовать более сложную структуру данных:
Жерар Юэ молния может быть определен практически для любой древовидной структуры данных и может использоваться для перемещения и внесения точечных изменений с постоянными затратами.Молнии легко понять.
Патерсон и Хинце пальчиковые деревья предлагают очень сложные представления последовательностей, которые, помимо прочего, позволяют эффективно изменять элементы в середине, но их трудно понять.
Хотя объекты, на которые ссылаются ссылки, в вашем коде одинаковы,
Я полагаю, что место для хранения самих ссылок
а структура списка
дублируется take.В результате, хотя объекты, на которые ссылаются, одинаковы,
а хвосты распределены между двумя списками,
"ячейки" для начальных частей дублируются.
Я не эксперт в функциональном программировании, но, возможно, с помощью какого-то дерева вы могли бы добиться дублирования только элементов log (n), поскольку вам пришлось бы воссоздавать только путь от корневого каталога к вставленному элементу.
Мне кажется, что ваш вопрос в первую очередь касается неизменяемые данные, а не функциональные языки как таковой.Данные действительно обязательно неизменяемы в чисто функциональном коде (см. ссылочная прозрачность), но я не знаю ни одного неигрушечного языка, который везде обеспечивает абсолютную чистоту (хотя Haskell подходит ближе всего, если вам нравятся подобные вещи).
Грубо говоря, ссылочная прозрачность означает, что никакой практической разницы не существует между переменной/выражением и значением, которое оно содержит/оценивает.Поскольку часть неизменяемых данных (по определению) никогда не изменится, ее можно тривиально идентифицировать по ее значению, и она должна вести себя неотличимо от любых других данных с тем же значением.
Следовательно, если мы решим не проводить семантического различия между двумя частями данных с одинаковым значением, у нас не будет причин когда-либо намеренно создавать повторяющееся значение.Итак, в случаях очевидного равенства (например, добавление чего-либо в список, передача его в качестве аргумента функции и т. д.), языки, где возможны гарантии неизменности, обычно, как вы говорите, обычно повторно используют существующую ссылку.
Аналогично, неизменяемый структуры данных обладают внутренней ссылочной прозрачностью своей структуры (но не содержания).Если предположить, что все содержащиеся значения также неизменяемы, это означает, что части структуры можно безопасно повторно использовать и в новых структурах.Например, хвост списка минусов часто можно использовать повторно;в вашем коде я ожидаю, что:
(skip 1 L) === (skip 2 M)
...бы также будь настоящим.
Однако повторное использование не всегда возможно;начальная часть списка, удаленная вашим skip Например, функцию нельзя использовать повторно.По той же причине добавление чего-либо в конец списка cons является дорогостоящей операцией, поскольку необходимо восстанавливать совершенно новый список, аналогично проблеме с объединением строк с нулевым завершением.
В таких случаях наивные подходы быстро приводят к ужасной производительности, которая вас беспокоила.Часто необходимо существенно переосмыслить фундаментальные алгоритмы и структуры данных, чтобы успешно адаптировать их к неизменяемым данным.Методы включают разбиение структур на многоуровневые или иерархические части для изоляции изменений, инвертирование частей структуры для предоставления дешевых обновлений часто изменяемым частям или даже сохранение исходной структуры вместе с коллекцией обновлений и объединение обновлений с оригиналом только на лету. когда осуществляется доступ к данным.
Поскольку вы здесь используете F#, я предполагаю, что вы хотя бы немного знакомы с C#;у бесценного Эрика Липперта есть множество постов о неизменяемых структурах данных в C#, которые, вероятно, просветят вас намного больше, чем я мог бы предоставить.В нескольких статьях он демонстрирует (достаточно эффективные) неизменяемые реализации стека, двоичного дерева и двусторонней очереди, среди прочего.Восхитительное чтение для любого .NET-программиста!
Вас могут заинтересовать стратегии сокращения выражений в функциональных языках программирования.Хорошая книга на эту тему Реализация языков функционального программирования, Саймон Пейтон Джонс, один из создателей Haskell.Обратите особое внимание на следующую главу. Сокращение графа лямбда-выражений поскольку оно описывает совместное использование общих подвыражений.Надеюсь, это поможет, но боюсь, это применимо только к ленивым языкам.
