¿Cómo es la manipulación no destructivo de memoria eficiente de las colecciones de lograr en la programación funcional?
 https://stackoverflow.com/questions/1993760
https://stackoverflow.com/questions/1993760
-
22-09-2019 - |
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
RussianPregunta
Estoy tratando de averiguar cómo la manipulación no destructiva de grandes colecciones se implementa en la programación funcional, es decir. cómo es posible alterar o eliminar elementos individuales sin tener que crear una nueva colección donde se duplicarán todos los elementos, incluso los no modificados, en la memoria. (Incluso si la colección original sería recolección de basura, yo esperaría que el consumo de memoria y el rendimiento general de una colección tan a ser horrible.)
Esto es lo lejos que tengo hasta ahora:
El uso de F #, se me ocurrió una insert función que divide una lista en dos partes e introduce un nuevo elemento en el medio, aparentemente sin la clonación de todos los elementos sin cambios:
// return a list without its first n elements:
// (helper function)
let rec skip list n =
if n = 0 then
list
else
match list with
| [] -> []
| x::xs -> skip xs (n-1)
// return only the first n elements of a list:
// (helper function)
let rec take list n =
if n = 0 then
[]
else
match list with
| [] -> []
| x::xs -> x::(take xs (n-1))
// insert a value into a list at the specified zero-based position:
let insert list position value =
(take list position) @ [value] @ (skip list position)
I después se comprueba si los objetos de una lista original son "reciclados" en las nuevas listas mediante el uso de .NET Object.ReferenceEquals:
open System
let (===) x y =
Object.ReferenceEquals(x, y)
let x = Some(42)
let L = [Some(0); x; Some(43)]
let M = Some(1) |> insert L 1
Los siguientes tres expresiones evaluar todos a true, lo que indica que el valor referido por x es re-utilizado tanto en las listas L y M, es decir. que sólo hay 1 copia de este valor en la memoria:
L.[1] === x
M.[2] === x
L.[1] === M.[2]
Mi pregunta:
¿Los lenguajes de programación funcionales general reutilizar los valores en lugar de clonar a una nueva ubicación en la memoria, o era yo sólo suerte con el comportamiento de F # 's? Suponiendo que la primera, ¿es así como la edición de la memoria razonablemente eficiente de las colecciones se puede implementar en la programación funcional?
(BTW .: Yo sé sobre el libro de Chris Okasaki estructuras de datos puramente funcional , pero aún no han tenido tiempo de leerlo a fondo.)
Solución
Estoy tratando de encontrar la manera manipulación no destructiva de gran colecciones se aplica en programación funcional, es decir. como es posible alterar o eliminar sola elementos sin tener que crear una colección completamente nueva donde todos elementos, incluso los no modificados, se duplicará en la memoria.
Esta página tiene algunas descripciones e implementaciones de estructuras de datos en C #. La mayoría de ellos provienen de Okasaki de puramente funcional Estructuras de datos , aunque el árbol AVL es mi propia aplicación ya que no estaba presente en el libro.
Ahora, ya que preguntas, sobre la reutilización de los nodos no modificados, tomemos un árbol binario simple:
type 'a tree =
| Node of 'a tree * 'a * 'a tree
| Nil
let rec insert v = function
| Node(l, x, r) as node ->
if v < x then Node(insert v l, x, r) // reuses x and r
elif v > x then Node(l, x, insert v r) // reuses x and l
else node
| Nil -> Node(Nil, v, Nil)
Tenga en cuenta que nos re-utilizar algunos de nuestros nodos. Digamos que empezamos con este árbol:
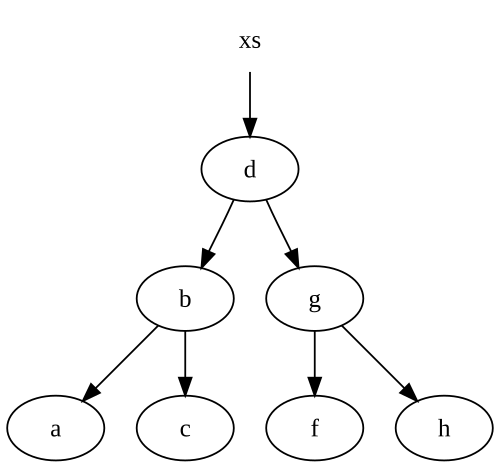
Cuando insertamos un e en el árbol, obtenemos un nuevo árbol, con algunos de los nodos que apuntan de nuevo a nuestro árbol original:

Si no tenemos una referencia al árbol xs arriba, entonces la basura voluntad .NET recoger los nodos sin referencias en vivo, específicamente thed, g y f nodos.
nodos en cuenta que sólo se ha modificado a lo largo del camino de nuestra insertado nodo . Esto es bastante típico en la mayoría de las estructuras de datos inmutables, incluidas las listas. Por lo tanto, el número de nodos creamos exactamente es igual al número de nodos que necesitamos para atravesar con el fin de insertar en nuestra estructura de datos.
¿Los lenguajes de programación funcional en general los valores de re-uso en lugar de clonar a una nueva ubicación en la memoria, o estaba simplemente suerte con F # s ' ¿comportamiento? Suponiendo que el anterior, es esta forma razonablemente eficaz memoria la edición de las colecciones puede ser implementado en la programación funcional?
Sí.
Listas, sin embargo, no son una muy buena estructura de datos, ya que la mayoría de las operaciones no triviales en ellos requieren tiempo O (n).
árboles binarios balanceados apoyan O (log n) inserciones, lo que significa que creamos O (log n) copias de cada inserto. Desde log 2 (10 ^ 15) es de ~ = 50, la sobrecarga es muy, muy pequeña para estas estructuras de datos particulares. Incluso si se mantiene en cada copia de cada objeto después de inserciones / eliminaciones, el uso de memoria aumentará a un ritmo de O (n log n) -. Muy razonable, en mi opinión
Otros consejos
¿Cómo es posible alterar o eliminar elementos individuales sin tener que crear una nueva colección donde se duplicarán todos los elementos, incluso los no modificados, en la memoria.
Esto funciona porque no importa qué tipo de colección, el punteros para los elementos se almacenan por separado de los propios elementos. (Excepción: algunos compiladores optimizará parte del tiempo, pero ellos saben lo que están haciendo.) Así, por ejemplo, puede tener dos listas que se diferencian sólo en los primeros apéndices de elementos y compartir:
let shared = ["two", "three", "four"]
let l = "one" :: shared
let l' = "1a" :: shared
Estos dos listas tienen la parte shared en común y sus primeros elementos diferente. Lo que es menos obvio es que cada lista también comienza con un par único, a menudo se llama una "célula contras":
-
Lista
lcomienza con un par que contiene un puntero a"one"y un puntero a la cola compartida. -
Lista
l'comienza con un par que contiene un puntero a"1a"y un puntero a la cola compartida.
Si sólo habíamos declarado l y quería alterar o eliminar el primer elemento para obtener l', nos gustaría hacer esto:
let l' = match l with
| _ :: rest -> "1a" :: rest
| [] -> raise (Failure "cannot alter 1st elem of empty list")
Hay costos constantes:
-
Split
len su cabeza y cola mediante el examen de la célula contras. -
Asignar un nuevo apuntando a cons cell
"1a"y la cola.
La nueva célula contras se convierte en el valor de la lista l'.
Si estás haciendo punto-como los cambios en el medio de una gran colección, por lo general se va a utilizar algún tipo de árbol de equilibrado que utiliza el tiempo y en el espacio logarítmico. Con menor frecuencia se puede usar una estructura de datos más sofisticada:
-
Gerard Huet cremallera se puede definir para cualquier estructura de datos de árbol similar y se puede utilizar para atravesar maquillaje y modificaciones puntuales a un costo constante. Cremalleras son fáciles de entender.
-
Paterson y Hinze de árboles dedos ofrecen representaciones muy sofisticadas de secuencias, que, entre otros trucos que permiten a los elementos de cambio en el medio de manera eficiente, pero son difíciles de entender.
Si bien los objetos referenciados son los mismos en su código,
Que creo el espacio de almacenamiento para las propias referencias
y la estructura de la lista
se duplica por take.
Como resultado, mientras que los objetos referenciados son los mismos,
y las colas son compartidos entre las dos listas,
se duplican las "células" para las porciones iniciales.
No soy un experto en la programación funcional, pero tal vez con algún tipo de árbol que podría lograr duplicación de (n) elementos solamente de registro, a medida que tendría que volver a crear sólo el camino de la raíz al elemento insertado.
Me suena igual que su pregunta se refiere primordialmente a de datos inmutables , las lenguas no funcionales por sí . Los datos son de hecho necesariamente inmutable en código puramente funcional (cf. referencial transparencia ), pero no estoy al tanto de cualquier lenguas no juguetes que hacen cumplir la pureza absoluta de todo el mundo (aunque Haskell se acerca más, si te gusta ese tipo de cosas).
En términos generales, los medios de transparencia referenciales que existe entre una variable / expresión y el valor que posee / evalúa a ninguna diferencia práctica. Debido a que una parte de los datos será inmutable (por definición) no cambio, puede ser trivialmente identificado con su valor y debe comportarse indistinguible de cualquier otro dato con el mismo valor.
Por lo tanto, al elegir a dibujar sin distinción semántica entre dos piezas de datos con el mismo valor, no tenemos ninguna razón para construir cada vez deliberadamente un valor duplicado. Por lo tanto, en caso de igualdad obvia (por ejemplo, añadir algo a una lista, pasándole como argumento de la función, & c.), Los idiomas en que son posibles garantías inmutabilidad general reutilizarán la referencia existente, como usted dice.
Asimismo, inmutable estructuras de datos poseer una transparencia referencial intrínseca de su estructura (aunque no su contenido). Suponiendo que todos los valores contenidos también son inmutables, esto significa que las piezas de la estructura de seguridad pueden ser reutilizados en nuevas estructuras también. Por ejemplo, la cola de una lista contras a menudo puede ser reutilizada; en su código, yo esperaría que:
(skip 1 L) === (skip 2 M)
... sería también ser verdad.
La reutilización no siempre es posible, sin embargo; la parte inicial de una lista eliminado por su función skip en realidad no puede ser reutilizado, por ejemplo. Por la misma razón, añadiendo algo al final de una lista contras es una operación costosa, ya que debe reconstruir una lista totalmente nueva, similar al problema con la concatenación de cadenas terminadas en cero.
En tales casos, los enfoques ingenuos obtener rápidamente en el ámbito de actuación horrible que estaban preocupados. A menudo, es necesario algoritmos fundamentales sustancialmente repensar y estructuras de datos para adaptarse con éxito a los datos inmutables. Las técnicas incluyen estructuras que se rompe en pedazos o en capas jerárquicas a cambios aislar, invirtiendo partes de la estructura para exponer actualizaciones baratas para piezas con frecuencia modificados, o incluso el almacenamiento de la estructura original junto a una colección de cambios y la combinación de los cambios con el original sobre la marcha solamente cuando se accede a los datos.
Dado que está utilizando F # aquí voy a suponer que eres al menos un poco familiarizado con C #; la inestimable Eric Lippert tiene una serie de mensajes en los datos inmutables estructuras en C # que probablemente le ilumine mucho más allá de lo que podía ofrecer. A lo largo de varios mensajes que demuestra (razonablemente eficientes) implementaciones inmutables de una pila, árbol binario, y la cola de doble extremo, entre otros. lectura agradable para cualquier programador .NET!
Usted puede estar interesado en las estrategias de reducción de expresiones en los lenguajes de programación funcionales. Un buen libro sobre el tema es La ejecución de la programación funcional Idiomas , por Simon Peyton Jones, uno de los creadores de Haskell. Echar un vistazo sobre todo en el capítulo siguiente Reducción Gráfico de Expresiones Lambda ya que describe el intercambio de subexpresiones comunes. Espero que ayuda, pero me temo que sólo se aplica a las lenguas perezosos.
