Come si ottiene una manipolazione non distruttiva delle raccolte efficiente in termini di memoria nella programmazione funzionale?
 https://stackoverflow.com/questions/1993760
https://stackoverflow.com/questions/1993760
-
22-09-2019 - |
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
RussianDomanda
Sto cercando di capire come viene implementata la manipolazione non distruttiva di grandi raccolte nella programmazione funzionale, ad es.come sia possibile alterare o rimuovere singoli elementi senza dover creare una collezione completamente nuova dove tutti gli elementi, anche quelli non modificati, verranno duplicati in memoria.(Anche se la raccolta originale venisse raccolta in modo spazzatura, mi aspetterei che l'impronta di memoria e le prestazioni generali di tale raccolta fossero orribili.)
Questo è il percorso che ho fatto fino ad ora:
Usando F#, ho trovato una funzione insert che divide un elenco in due parti e introduce un nuovo elemento nel mezzo, apparentemente senza clonare tutti gli elementi invariati:
// return a list without its first n elements:
// (helper function)
let rec skip list n =
if n = 0 then
list
else
match list with
| [] -> []
| x::xs -> skip xs (n-1)
// return only the first n elements of a list:
// (helper function)
let rec take list n =
if n = 0 then
[]
else
match list with
| [] -> []
| x::xs -> x::(take xs (n-1))
// insert a value into a list at the specified zero-based position:
let insert list position value =
(take list position) @ [value] @ (skip list position)
Ho quindi verificato se gli oggetti di un elenco originale vengono "riciclati" in nuovi elenchi utilizzando .NET Object.ReferenceEquals:
open System
let (===) x y =
Object.ReferenceEquals(x, y)
let x = Some(42)
let L = [Some(0); x; Some(43)]
let M = Some(1) |> insert L 1
Le seguenti tre espressioni restituiscono tutte a true, indicando che il valore di cui all'art x viene riutilizzato in entrambi gli elenchi L E M, cioè.che c'è solo 1 copia di questo valore in memoria:
L.[1] === x
M.[2] === x
L.[1] === M.[2]
La mia domanda:
I linguaggi di programmazione funzionale generalmente riutilizzano i valori invece di clonarli in una nuova posizione di memoria, o sono stato solo fortunato con il comportamento di F#?Supponendo il primo, è questo il modo in cui è possibile implementare nella programmazione funzionale la modifica delle raccolte in modo ragionevolmente efficiente in termini di memoria?
(A proposito:Lo so Il libro di Chris Okasaki Strutture dati puramente funzionali, ma non ho ancora avuto il tempo di leggerlo attentamente.)
Soluzione
Sto cercando di capire come manipolazione non distruttiva di grandi collezioni è implementato in programmazione funzionale, cioè. com'è possibile alterare o rimuovere singola elementi senza dover creare un completamente nuova collezione dove tutto elementi, anche quelli non modificati, sarà duplicato in memoria.
Questa pagina ha alcune descrizioni e le implementazioni di strutture di dati in F #. La maggior parte di loro provengono da Okasaki di puramente funzionale Strutture dati , anche se l'albero AVL è la mia propria implementazione in quanto non era presente nel libro.
Ora, dal momento che hai chiesto, circa il riutilizzo nodi non modificati, facciamo un semplice albero binario:
type 'a tree =
| Node of 'a tree * 'a * 'a tree
| Nil
let rec insert v = function
| Node(l, x, r) as node ->
if v < x then Node(insert v l, x, r) // reuses x and r
elif v > x then Node(l, x, insert v r) // reuses x and l
else node
| Nil -> Node(Nil, v, Nil)
Si noti che si ri-utilizziamo alcuni dei nostri nodi. Diciamo che partiamo con questo albero:
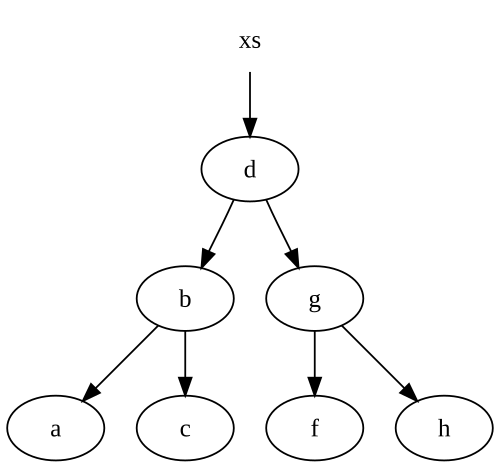
Quando si inserisce un e nella struttura ad albero, otteniamo un nuovo albero, con alcuni dei nodi che puntano al nostro albero originale:

Se non abbiamo un riferimento all'albero xs sopra, quindi .NET sarà spazzatura raccogliere eventuali nodi senza riferimenti dal vivo, in particolare thed, nodi g e f.
nodi notare che abbiamo modificato solo lungo il cammino della nostra nodo inserito . Questo è abbastanza tipico in strutture di dati più immutabili, inclusi gli elenchi. Così, il numero di nodi che creiamo è esattamente uguale al numero di nodi che dobbiamo percorrere per inserire nella nostra struttura dati.
Fare linguaggi di programmazione funzionale generalmente valori riutilizzare anziché li clonazione in una nuova posizione di memoria, o ero fortunato con F # 's comportamento? Supponendo che il primo, è questo modo ragionevolmente memoria-efficiente la modifica delle collezioni può essere implementato in programmazione funzionale?
Sì.
Elenchi, tuttavia, non sono una buona struttura di dati, poiché la maggior parte delle operazioni non banali su di essi richiedono O (n).
Balanced alberi binari di supporto O (log n) inserti, il che significa che creiamo O (log n) copie su ogni inserto. Dal momento che log 2 (10 ^ 15) è ~ = 50, l'overhead è molto molto piccola per queste particolari strutture di dati. Anche se si mantiene intorno a ogni copia di ogni oggetto dopo inserti / cancella, l'uso della memoria aumenterà ad un tasso di O (n log n) -. Molto ragionevole, a mio parere
Altri suggerimenti
Come è possibile alterare o rimuovere singoli elementi senza dover creare una collezione completamente nuova dove tutti gli elementi, anche quelli non modificati, verranno duplicati in memoria.
Funziona perché non importa quale tipo di raccolta, il file puntatori agli elementi vengono memorizzati separatamente dagli elementi stessi.(Eccezione:alcuni compilatori ottimizzeranno una parte del tempo, ma sanno cosa stanno facendo.) Quindi, ad esempio, puoi avere due elenchi che differiscono solo nel primo elemento e condividono code:
let shared = ["two", "three", "four"]
let l = "one" :: shared
let l' = "1a" :: shared
Questi due elenchi hanno il shared parte in comune e i loro primi elementi diversi.Ciò che è meno ovvio è che ogni elenco inizia anche con una coppia univoca, spesso chiamata "cella contro":
Elenco
linizia con una coppia contenente un puntatore a"one"e un puntatore alla coda condivisa.Elenco
l'inizia con una coppia contenente un puntatore a"1a"e un puntatore alla coda condivisa.
Se solo avessimo dichiarato l e volevo farlo alterare o rimuovere il primo elemento ottenere l', faremmo questo:
let l' = match l with
| _ :: rest -> "1a" :: rest
| [] -> raise (Failure "cannot alter 1st elem of empty list")
Il costo è costante:
Diviso
lnella sua testa e coda esaminando la cella contro.Assegna una nuova cella contro a cui punta
"1a"e la coda.
La nuova cella contro diventa il valore di list l'.
Se stai apportando modifiche puntuali nel mezzo di una grande raccolta, in genere utilizzerai una sorta di albero bilanciato che utilizza tempo e spazio logaritmici.Meno frequentemente potresti utilizzare una struttura dati più sofisticata:
Di Gerard Huet cerniera può essere definito praticamente per qualsiasi struttura dati ad albero e può essere utilizzato per attraversare e apportare modifiche puntuali a costo costante.Le cerniere sono facili da capire.
Paterson e Hinze alberi delle dita offrono rappresentazioni molto sofisticate di sequenze, che tra gli altri trucchi consentono di cambiare gli elementi al centro in modo efficiente, ma sono difficili da capire.
Mentre gli oggetti di riferimento sono gli stessi nel codice,
Ho beleive lo spazio di archiviazione per i riferimenti stessi
e la struttura della lista
è duplicato dal take.
Come risultato, mentre gli oggetti di riferimento sono uguali,
e le code sono condivisi tra le due liste,
le "celle" per i tratti iniziali sono duplicati.
Io non sono un esperto di programmazione funzionale, ma forse con qualche tipo di albero che si potrebbe ottenere la duplicazione degli elementi solo log (N), come si sarebbe ricreare solo il percorso dalla radice all'elemento inserito.
Sembra a me come la tua domanda è principalmente di Dati immutabili , le lingue non funzionali per se . I dati è infatti necessariamente immutabili nel codice puramente funzionale (cfr trasparenza referenziale ), ma io non sono a conoscenza di lingue non giocattolo che applicano la purezza assoluta in tutto il mondo (anche se Haskell si avvicina di più, se vi piace questo genere di cose).
In parole povere, la trasparenza referenziale significa che esiste alcuna differenza pratica tra una variabile / espressione e il valore che detiene / a viene valutata. A causa di un pezzo di dati immutabili sarà (per definizione) non cambiano mai, può essere banalmente identificato con il suo valore e deve comportarsi indistinguibile da qualsiasi altro dato con lo stesso valore.
Quindi, eleggendo per disegnare alcuna distinzione semantica tra due pezzi di dati con lo stesso valore, non abbiamo alcun motivo per costruire mai deliberatamente un valore duplicato. Così, in caso di evidente uguaglianza (ad esempio, l'aggiunta di qualcosa a un elenco, passando come argomento di funzione, ecc.), Le lingue in cui sono possibili garanzie immutabilità generalmente riutilizzare il riferimento esistente, come dici tu.
Analogamente, immutabili strutture di dati possiedono una trasparenza referenziale intrinseca della loro struttura (anche se non il loro contenuto). Supponendo tutti i valori contenuti sono anche immutabile, ciò significa che pezzi della struttura possono tranquillamente essere riutilizzati in nuove strutture pure. Ad esempio, la coda di una lista cons spesso può essere riutilizzato; nel codice, mi aspetterei che:
(skip 1 L) === (skip 2 M)
... farebbe anche essere vero.
Il riutilizzo non è sempre possibile, però; la parte iniziale di un elenco rimossa dalla funzione skip non può realmente essere riutilizzato, per esempio. Per lo stesso motivo, aggiungendo qualcosa alla fine di un elenco dei contro è un'operazione costosa, in quanto deve ricostruire un intero nuovo elenco, simile al problema con la concatenazione di stringhe null-terminate.
In questi casi, gli approcci ingenui ottenere rapidamente nel regno della performance terribile si erano preoccupati. Spesso, è necessario ripensare sostanzialmente algoritmi e strutture dati fondamentali di adattarsi con successo ai dati immutabili. Tecniche includono strutture spezzettamento stratificate o gerarchiche per isolare modifiche, parti inversione della struttura per esporre aggiornamenti economiche parti frequente-modificata, o addirittura memorizzare la struttura originaria accanto ad una raccolta di aggiornamenti e combinando gli aggiornamenti con l'originale sul fly unico quando i dati si accede.
Dal momento che si sta utilizzando F # qui ho intenzione di assumere sei almeno un po 'familiarità con C #; l'inestimabile Eric Lippert ha un dei messaggi su dati immutabili strutture in C # che probabilmente vi illumini ben oltre quello che ho potuto fornire. Nel corso di diversi posti dimostra (ragionevolmente efficienti) implementazioni immutabili di una pila, albero binario, e Deque, tra gli altri. lettura piacevole per qualsiasi programmatore .NET!
Si può essere interessati a strategie di riduzione di espressioni in linguaggi di programmazione funzionale. Un buon libro su questo argomento è L'attuazione di linguaggi di programmazione funzionali , da Simon Peyton Jones, uno dei creatori di Haskell. Date un'occhiata in particolare al capitolo seguente Grafico Riduzione del Lambda Expressions in quanto descrive la condivisione di sottoespressioni comuni. Speranza che aiuta, ma ho paura che si applica solo alle lingue pigri.
